Teaching Gemma to Route GCP Infrastructure Requests into Strict JSON Tool Calls


The Problem
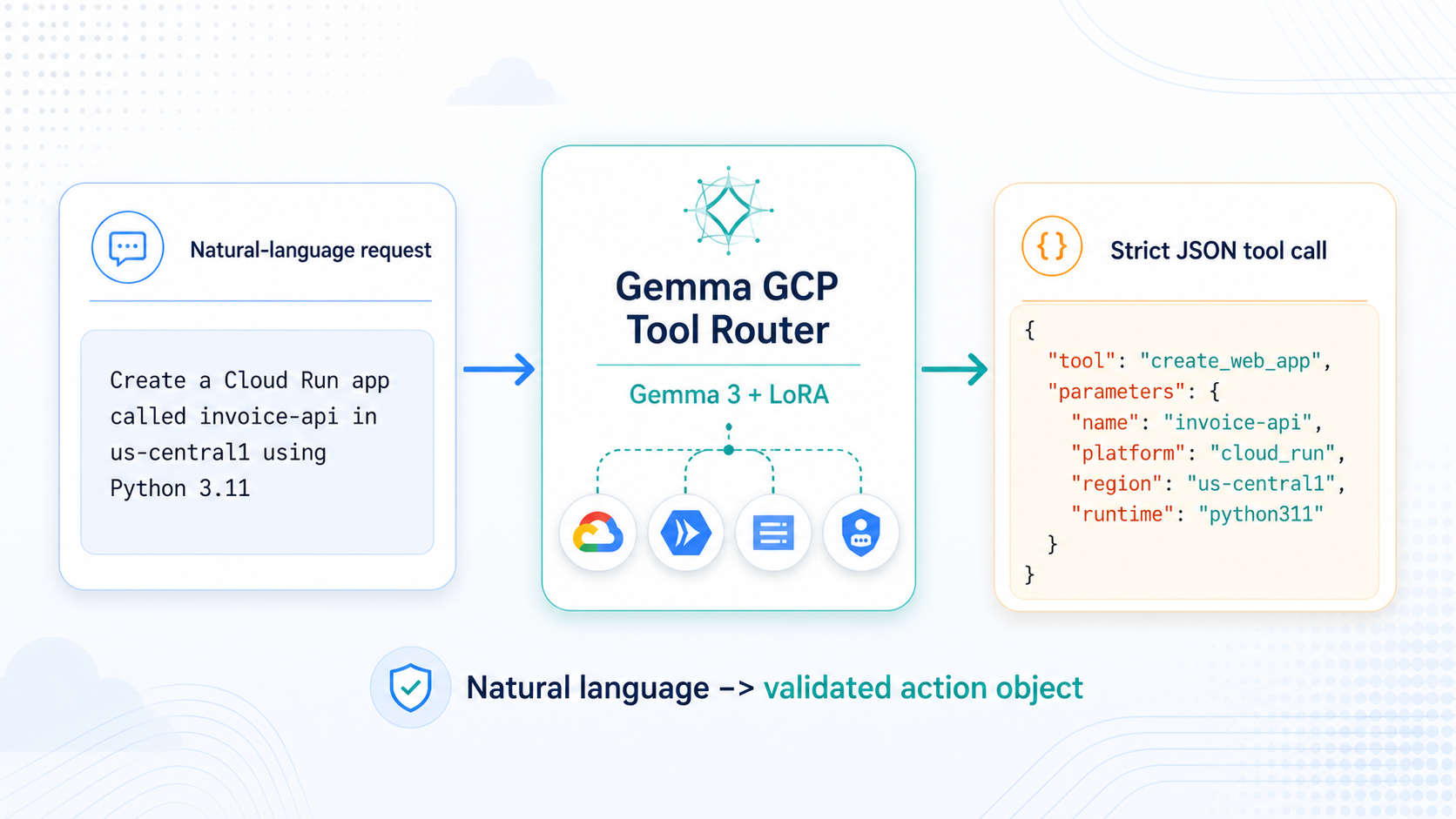
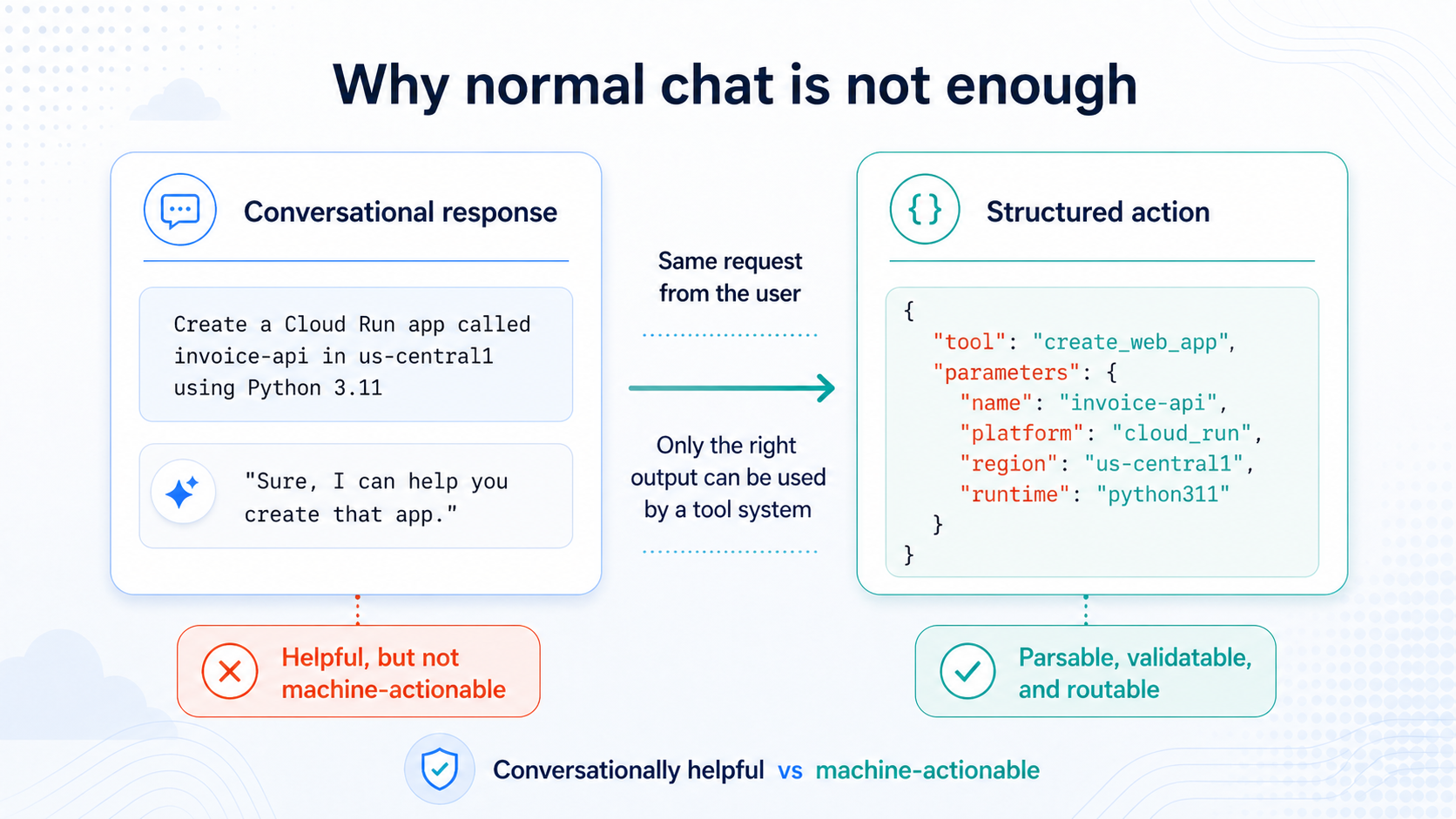
For agents and automation systems, a helpful paragraph is often the wrong output.
If someone asks:
Create a Cloud Run app called invoice-api in us-central1 using Python 3.11
a normal chat model might reply:
Sure, I can help you create that app.
That is conversationally reasonable. It acknowledges the request. It sounds helpful. But for a deployment assistant, it does not actually move the system forward.
A tool-based system needs something more precise. It needs an action object that can be parsed, validated, logged, and routed to the correct backend capability:
{
"tool": "create_web_app",
"parameters": {
"name": "invoice-api",
"platform": "cloud_run",
"region": "us-central1",
"runtime": "python311"
}
}
That difference is the center of this project.
The problem is not simply whether a model understands the request. Most modern instruction models can infer that the user wants some kind of cloud deployment. The harder question is whether the model can turn that understanding into a strict, machine-readable object that another system can safely consume.
For this release, the target behavior is simple: plain English GCP request -> strict JSON tool call
But that simple transformation contains several smaller tasks:
- identify the user’s intent
- choose the correct tool
- extract the required fields
- normalize values into the expected format
- avoid extra prose, markdown, or role labels
- produce JSON that matches a known schema exactly
For example, the model should not merely understand that “Python 3.11” is a runtime. It needs to emit python311. It should not merely understand that “Cloud Run” is a deployment platform. It needs to emit cloud_run. It should not add a friendly explanation before or after the object, because that makes the output harder for a downstream router to trust.
This is a small version of a real agent problem: intent routing, field extraction, value normalization, and schema compliance.
The broader question is:
Can a small open model learn to reliably select a cloud automation tool, normalize its parameters, and emit only the exact JSON object a downstream router expects?
Release 1.3.0 is not a full infrastructure agent yet. It does not provision real cloud resources, plan multi-step deployments, or replace validation and authorization layers.
That is the direction of the project, but this release focuses on the routing layer first. The reason is simple: before an agent can safely execute infrastructure changes, it needs to reliably translate user intent into a validated action object.
If that layer is unreliable, everything downstream becomes fragile. So this release focuses on one narrow but important skill:
Turning intent into a validated GCP action object.
From there, the project can expand toward a fuller GCP agent: more tools, better ambiguity handling, policy checks, dry-run validation, multi-step plans, and eventually controlled execution through a secure tool layer.
What This Project Is
Gemma GCP Tool Router is a Hugging Face project built around one narrow behavior:
Given a natural-language GCP infrastructure request, output exactly one JSON tool call.
Release 1.3.0 supports 15 GCP-flavored single-action tools:
create_web_appcreate_storage_bucketcreate_pubsub_topiccreate_cloud_sql_instancecreate_service_accountcreate_cloud_functioncreate_secretcreate_scheduler_jobgrant_project_iam_rolecreate_vpc_connectorcreate_cloud_run_jobcreate_artifact_registry_repocreate_bigquery_datasetcreate_cloud_tasks_queuecreate_firestore_database
The model has to do four things at once:
- choose the correct tool
- extract the required fields
- normalize values into the expected enum or type
- output only JSON, with no role labels, markdown fences, or extra prose
That sounds simple, but the useful behavior is in the details.
For example, the model has to learn that:
Node.js 20should becomenodejs20Python 3.11should becomepython311App Engineshould becomeapp_engineCloud Runshould becomecloud_run- IAM roles need exact prefixes like
roles/storage.admin - Cloud Run Jobs are not the same thing as Cloud Run services
- a scheduler target should map to
target_uri - BigQuery datasets need
default_table_expiration_days, including0when no expiration is requested
That is the key point: this is not generic JSON formatting.
The model is learning a constrained routing problem: map a user’s request to one supported tool, fill the exact schema for that tool, and normalize every value into the shape a downstream system expects.
Training Setup
The project uses a Hugging Face-native workflow: the dataset lives on the Hub, training runs through Hugging Face Jobs, the LoRA adapter is published back as a model artifact, and the final router is exposed through a Space demo.
That setup was useful because it kept the experiment reproducible. The dataset, adapter, evaluation flow, and demo were all part of the same public project surface instead of being scattered across local scripts and one-off training runs.
| Component | Choice |
|---|---|
| Base model | google/gemma-3-1b-it |
| Method | LoRA supervised fine-tuning |
| Platform | Hugging Face Jobs |
| Dataset | Jayteare/gemma-gcp-tool-router-1-3-data |
| Adapter | Jayteare/gemma-gcp-tool-router-1-3-lora |
| Public demo | Jayteare/gemma-gcp-tool-router |
| Split | 208 train examples and 55 held-out eval examples |
I used google/gemma-3-1b-it as the base model because it is small enough to fine-tune quickly, but capable enough to follow instructions and produce structured outputs. That made it a good fit for a focused routing experiment. The goal was not to use the largest possible model. The goal was to see whether a compact instruction model could learn a narrow, schema-driven behavior.
LoRA was a good fit for the same reason. Instead of fully fine-tuning every model weight, the training run learns a lightweight adapter that shifts the model toward the routing task. That keeps the experiment smaller, faster, and easier to iterate on. It also makes the final artifact easier to publish and reuse, because the adapter can be stored separately from the base model.
The dataset split was intentionally modest: 208 training examples and 55 held-out evaluation examples. The goal was not to brute-force the task with a huge synthetic dataset. I wanted to understand whether the model could learn the routing behavior from a compact set of targeted examples.
The held-out set matters because the target behavior is not memorization. A useful router needs to handle new wording, normalize fields, choose between similar tools, and keep the output machine-readable. If the model only succeeds on training-style prompts, it is not really learning the routing layer. It is just fitting the examples.
The workflow was intentionally compact:
- build a focused dataset
- train a LoRA adapter
- evaluate on held-out prompts
- inspect exact failures
- add targeted examples for recurring failure modes
- retrain and compare
That loop was more useful than generating a large synthetic dataset upfront. The goal was not more examples for their own sake. The goal was better coverage of the details that actually break tool routing.
For example, early failures showed up around IAM role prefixes, Cloud Run Jobs versus Cloud Run services, Scheduler target_uri extraction, BigQuery expiration defaults, and sequence length truncation on long schema prompts.
Those failures were useful because they made the next iteration obvious.
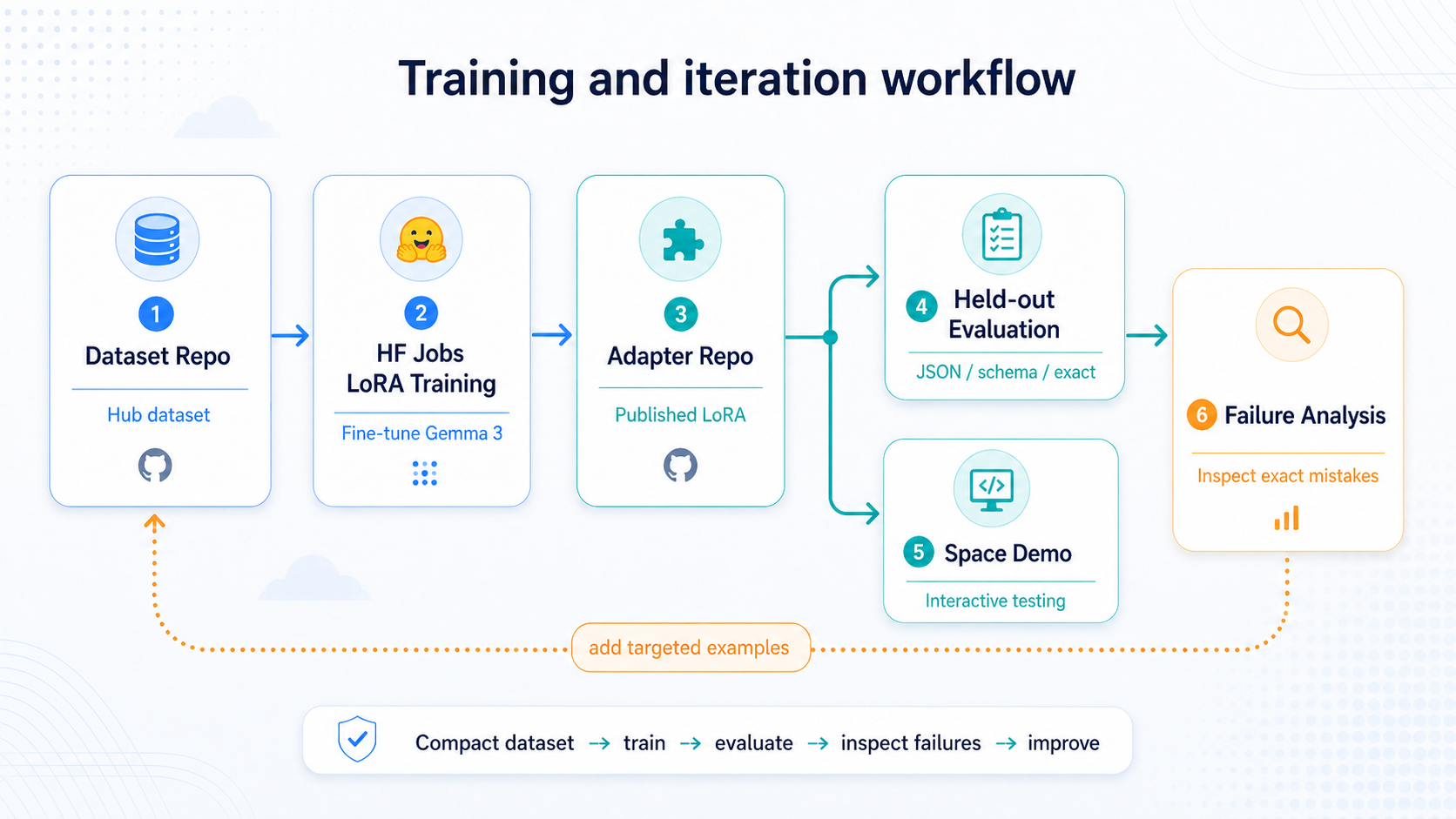
If the model emitted storage.admin instead of roles/storage.admin, the dataset needed more IAM examples that reinforced exact role formatting. If the model confused a Cloud Run Job with a Cloud Run service, the dataset needed clearer contrastive examples between those two tools. If BigQuery prompts without expiration omitted default_table_expiration_days: 0, the dataset needed examples where “no expiration” still produced an explicit value.
That is the pattern I wanted: evaluate first, then add data for the failures that actually appear.
This made the project feel less like a one-off notebook and more like a small release pipeline.
The dataset defined the behavior. Hugging Face Jobs trained the adapter. The adapter repo captured the model artifact. The held-out evaluation measured whether the behavior actually improved. The Space made the result easy to test interactively.
That structure also leaves room for future releases. New tools can be added to the dataset, old examples can stay as regression coverage, and the adapter can be retrained against a broader schema without losing the evaluation trail from previous versions.
Baseline: What Base Gemma Did
Before fine-tuning, I tested the base google/gemma-3-1b-it model on the held-out prompts.
This baseline was important because it gave me a real comparison point. Without it, the fine-tuned adapter could look impressive in isolation, but I would not know whether it had actually improved the behavior that mattered.
The base model was not useless. It often understood the general shape of the task. It could infer that the user wanted some kind of structured response, and it frequently produced output that looked JSON-like.
That is an important distinction. The model was often directionally correct, but not operationally reliable. For a chat interface, directionally correct might be enough. For a tool router, it is not.
A tool router needs the output to be parseable, schema-valid, and safe to pass into the next layer of the system. If the model adds prose around the JSON, uses the wrong key, omits a required field, or chooses the wrong tool, the downstream system has to reject the action.
Common base-model failures included:
- adding text around the JSON
- using wrong or missing fields
- producing malformed JSON
- copying schema-like placeholder values
- confusing Cloud Run Jobs with Cloud Run services
- confusing service account creation with IAM role grants
- using
targetinstead oftarget_uri - omitting required defaults, such as BigQuery expiration values
- failing to normalize runtime and IAM role strings
- selecting the wrong tool for similar infrastructure requests
Those failures are subtle but important.
For example, an output can be valid JSON and still be wrong. If a scheduler job uses target instead of target_uri, the object may parse, but it does not match the schema. If an IAM grant emits storage.admin instead of roles/storage.admin, the model understood the intent but failed the exact value normalization. If a Cloud Run Job is routed as a Cloud Run service, the output may look plausible while still calling the wrong backend capability.
That distinction matters.
JSON-looking output is not the same as a safe tool call.
A downstream tool layer should not have to guess what the model meant. It should receive an object with exact keys, normalized values, and a known schema. Anything less should be treated as an invalid action.
That is why the baseline was useful. It showed that the base model already had some general instruction-following ability, but it did not have the strict routing behavior needed for automation.
The fine-tuning task was not to teach the model what GCP is from scratch. It was to make the model reliable at the boundary where natural language becomes a machine-readable action.
Evaluation
The evaluation focused on strict behavior, not subjective quality.
For this project, I did not want to judge outputs by whether they “looked about right.” A response can look reasonable to a human and still be unusable by a tool router. The important question was whether the output could be safely consumed by another system without guessing, cleanup, or manual correction.The evaluation measured three main behaviors:
JSON only
The entire response parsed as JSON, with no extra text before or after it.
Schema valid
The parsed object matched one supported tool schema, including the expected tool name and allowed parameter keys.
Exact match
The response was JSON-only and exactly equal to the expected output for that held-out prompt.
The strictest metric was Exact match. That is the one I cared about most.
For tool routing, the difference between almost-right and exactly-right is significant. A missing field, a wrong enum, an extra key, or a slightly different parameter name can break an automation pipeline.
For example, these outputs might look close to a human:
{
"tool": "create_scheduler_job",
"parameters": {
"name": "monthly-close",
"region": "us-west1",
"schedule": "0 4 1 * *",
"target": "https://example.com/monthly-close"
}
}
{
"tool": "grant_project_iam_role",
"parameters": {
"principal": "user:ops@example.com",
"role": "storage.admin",
"project_id": "analytics-prod"
}
}
But both should fail strict evaluation.
The first uses target instead of the expected target_uri. The second uses storage.admin instead of the normalized IAM role string roles/storage.admin.
Those are not cosmetic differences. They are interface mismatches.
That is why the evaluation separated “JSON only” from “Schema valid” and “Exact match.” A model can produce clean JSON and still choose the wrong tool, use the wrong key, omit a required default, or output a value in the wrong format.
The held-out prompts were not included in training. They were used to test whether the model could generalize the routing behavior to new wording while preserving exact schema shape.
In other words, the evaluation asked:
- Did the model output only JSON?
- Did it choose a supported tool?
- Did it use the right parameter keys?
- Did it normalize values correctly?
- Did it avoid extra prose or markdown fences?
- Did the final object exactly match the expected action?
That made the result much easier to interpret. Instead of relying on vibes, the evaluation checked whether the model produced the exact object a downstream router would expect.
The Result
Release 1.3.0 reached a clean held-out pass.
The evaluation compared three versions:
- the base
google/gemma-3-1b-itmodel - the frozen
1.2LoRA adapter - the newly fine-tuned
1.3LoRA adapter
That comparison was useful because it showed three different levels of behavior. The base model tested what Gemma could do without task-specific training. The frozen 1.2 adapter tested whether the earlier router generalized to the expanded 1.3 schema. The 1.3 adapter tested whether targeted fine-tuning on the new schema closed the gap.
-
Base
google/gemma-3-1b-it- JSON only:
44/55 - Schema valid:
5/55 - Exact match:
1/55
- JSON only:
-
Frozen
1.2LoRA adapter- JSON only:
52/55 - Schema valid:
36/55 - Exact match:
33/55
- JSON only:
-
Fine-tuned
1.3LoRA adapter- JSON only:
55/55 - Schema valid:
55/55 - Exact match:
55/55
- JSON only:
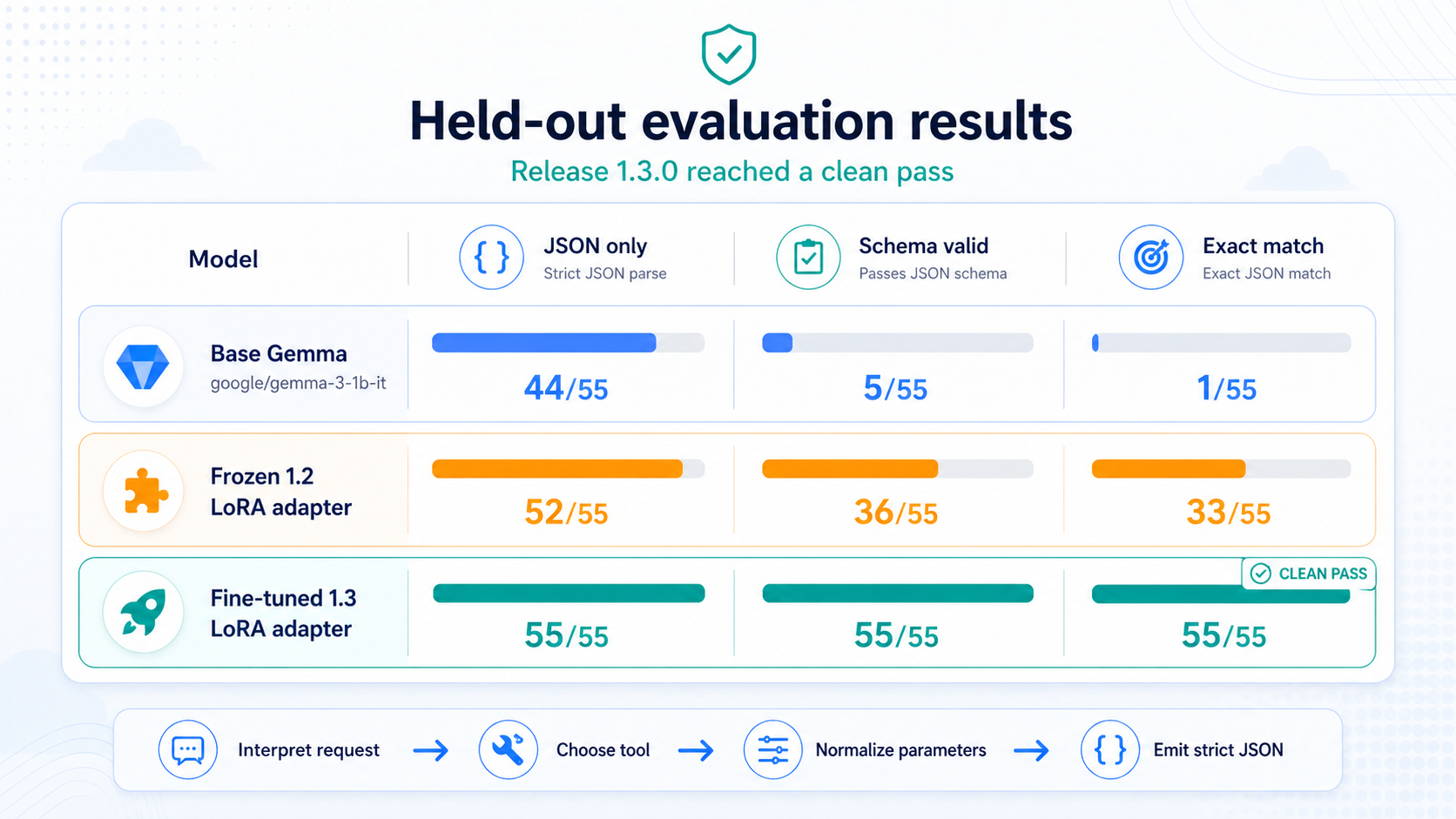
The base model often understood the rough shape of the task, but it was unreliable. It could emit JSON-looking text while still choosing the wrong tool, adding extra keys, copying schema placeholders, or missing required parameters.
The frozen 1.2 adapter was better. It had already learned much of the routing behavior from the earlier release, but it failed on parts of the expanded 1.3 schema. That was useful because it showed the earlier adapter had not magically generalized to the new tools. The model needed targeted examples for the new action types and schema details.
After training the 1.3 adapter, the model produced strict, schema-valid JSON for every held-out example.
The most important part is not just that the adapter improved the output. It improved the exact behavior that matters for tool routing:
interpret request -> choose tool -> normalize parameters -> emit strict JSONWhat Was Actually Hard
The interesting part was not getting Gemma to output something that looked like JSON.
The hard part was getting it to output the exact right JSON consistently.
That distinction matters because many model outputs can look correct at a glance while still being unusable by a tool router. A response might parse as JSON, include a plausible tool name, and contain fields that seem related to the request, but still fail because one key is wrong, one value is not normalized, or the selected tool is slightly off.
Some of the hardest failures were small schema details:
- IAM roles needed exact prefixes, such as
roles/storage.admin, notstorage.admin. - BigQuery datasets needed
default_table_expiration_days: 0when no expiration was requested. - Pub/Sub topics needed
message_retention_days, not extra keys liketopic. - Cloud Run Jobs needed to stay distinct from Cloud Run services.
- Cloud Tasks queues needed queue rate and concurrency fields, not scheduler-job fields.
- Scheduler requests needed
target_uri, nottarget. - The response needed to be JSON only, with no role labels, markdown fences, or explanatory text.

These are not dramatic failures in a chat demo. In fact, many of them look small. But in an automation system, small schema errors are exactly the kind of thing that break the handoff between the model and the tool layer.
For example, if the model emits:
{
"tool": "grant_project_iam_role",
"parameters": {
"principal": "user:ops@example.com",
"role": "storage.admin",
"project_id": "analytics-prod"
}
}
the intent is understandable, but the role value is not normalized. The expected value is:
"roles/storage.admin"
That is not a style preference. It is the difference between a valid tool argument and an invalid one.
The same pattern showed up in scheduler prompts. A human can infer that target means the URL the scheduler should call, but the schema expects target_uri. If the model emits the wrong key, the router should reject the object rather than guess.
One training run also failed because the sequence length was too short and truncated the long schema prompt. That was a useful reminder that failures are not always about the dataset. Sometimes the training setup itself prevents the model from seeing enough of the instruction context. Increasing the training sequence length fixed that class of failure.
The broader lesson was that tool routing lives in the details.
A model can understand the user request semantically and still produce an object that a router should reject. That is why the evaluation focused on strict schema validity and exact match rather than a subjective “looks right” score.
For this kind of system, “almost right” is not good enough. The output has to be exact enough that a downstream validator can say yes or no without interpreting the model’s intent.
What This Proves
This project does not prove that a small model can safely operate cloud infrastructure by itself.
It should not be read as “Gemma can manage GCP now.” Release 1.3.0 does not call real cloud APIs, enforce policy, check permissions, create Terraform, validate costs, or reason through multi-step architecture decisions.
What it proves is narrower, but still useful:
A small open model can learn a realistic agent subskill: selecting a tool, normalizing parameters, and emitting strict JSON.
That subskill matters because many agent systems depend on a clean handoff between natural language and executable actions. Before an agent can safely invoke a cloud API, it needs to translate user intent into something structured enough for another layer to validate.
In this project, that structured layer is a JSON tool call.
The model has to move from:
Create a Cloud Run Job named media-transcode in us-east1 using Go with 12 tasks and 2048 MB
to an object shaped like:
{
"tool": "create_cloud_run_job",
"parameters": {
"name": "media-transcode",
"region": "us-east1",
"runtime": "go122",
"task_count": 12,
"memory_mb": 2048
}
}
That is a small step compared with a full infrastructure agent, but it is a necessary one.
This kind of routing layer is useful for:
- agent tool routing
- MCP-style servers
- deployment assistants
- structured cloud automation
- schema-first AI workflows
- validation-first infrastructure agents
In other words, this is not a full infrastructure agent yet. It is the routing layer that a safer infrastructure agent would need before invoking real cloud APIs.
The strongest lesson was not just that fine-tuning worked. It was that evaluation made the work concrete.
Instead of saying:
The model seems better.
I could say:
Base Gemma: 1/55 exact match.
Frozen 1.2 adapter: 33/55 exact match.
Fine-tuned 1.3 adapter: 55/55 exact match.
That turns a demo into evidence.
It also gives the project a practical development loop. When the model fails, the failure is not vague. It is inspectable. The output either matches the schema or it does not. The role string is normalized or it is not. The tool is correct or it is not.
That makes the next iteration easier to reason about.
The long-term goal is to keep expanding this routing layer into a fuller GCP agent. But the foundation has to be reliable first. A planning agent that cannot produce valid action objects will be fragile no matter how good its natural-language reasoning looks.
So the main result of release 1.3.0 is this: the structured action layer can be trained, measured, and improved.
Why This Matters for Agentic Infrastructure
A lot of agent demos stop at natural-language planning.
The model explains what it would do. It produces a reasonable sequence of steps. It sounds like an assistant that understands the task.
But actual systems need more than plans. They need stable interfaces.
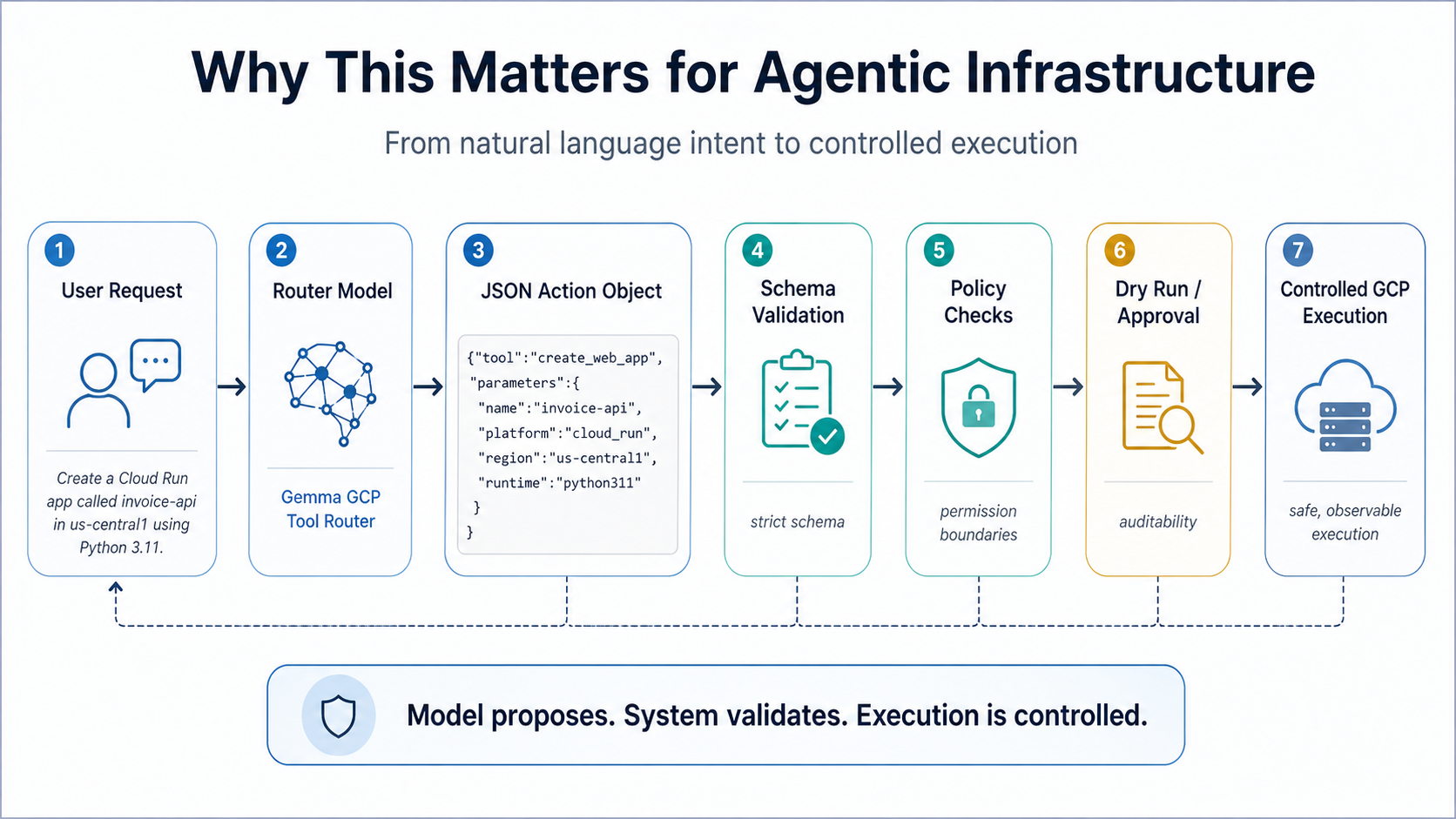
If an agent is going to call a deployment tool, create an IAM binding, schedule a job, provision a connector, or trigger a workflow, the output needs to be more than plausible. It needs to be structured enough that another layer can validate it before anything executes.
That validation layer is what separates a demo from a system.
A natural-language plan might say:
Create a Cloud Run service, attach a service account, store the API key in Secret Manager, and schedule a nightly job.
That is useful as a planning artifact, but it is not yet an executable interface. A safer system needs to translate that plan into constrained actions with known schemas.
For example, one action might become:
{"tool":"create_secret","parameters":{"name":"api-key","region":"us-central1","replication":"automatic"}}
Once the action is structured, the rest of the system can do its job.
It can check whether the tool is supported. It can validate required fields. It can reject unsupported regions or runtimes. It can enforce policy. It can log the proposed action. It can run a dry-run. It can ask for confirmation before execution.
That is the larger pattern this project is exploring.
The model does not need to be a full cloud architect at this stage. It needs to be a reliable router for a constrained domain.
That constraint is not a weakness. It is the safety boundary.
A narrow router with strict schemas is easier to evaluate, easier to reject, and easier to improve than a broad agent that can emit arbitrary instructions. If the model output has to match a schema exactly, then failure becomes visible. The system does not have to guess what the model meant.
That is the core idea behind this release:
natural language intent -> validated action object -> controlled execution layer
This is also why small models are interesting for agentic infrastructure. A smaller model does not have to solve the entire cloud automation problem by itself. It can own a specific layer: routing user intent into structured actions. Heavier models, deterministic validators, policy engines, and execution tools can handle the rest.
That suggests a useful pattern:
- keep the task narrow
- define strict schemas
- evaluate with exact outputs
- reject malformed actions
- add targeted data for recurring failures
- expand the tool surface gradually
- put validation and authorization between the model and execution
In that architecture, the model is not trusted because it sounds confident. It is trusted only when its output survives validation.
That is the important shift.
For infrastructure agents, the goal is not just better chat. The goal is reliable handoff between language, schema, policy, and execution.
Gemma GCP Tool Router is a small step in that direction. It focuses on the routing layer first because that layer has to be boringly reliable before a full GCP agent can be safe or useful.
Try It
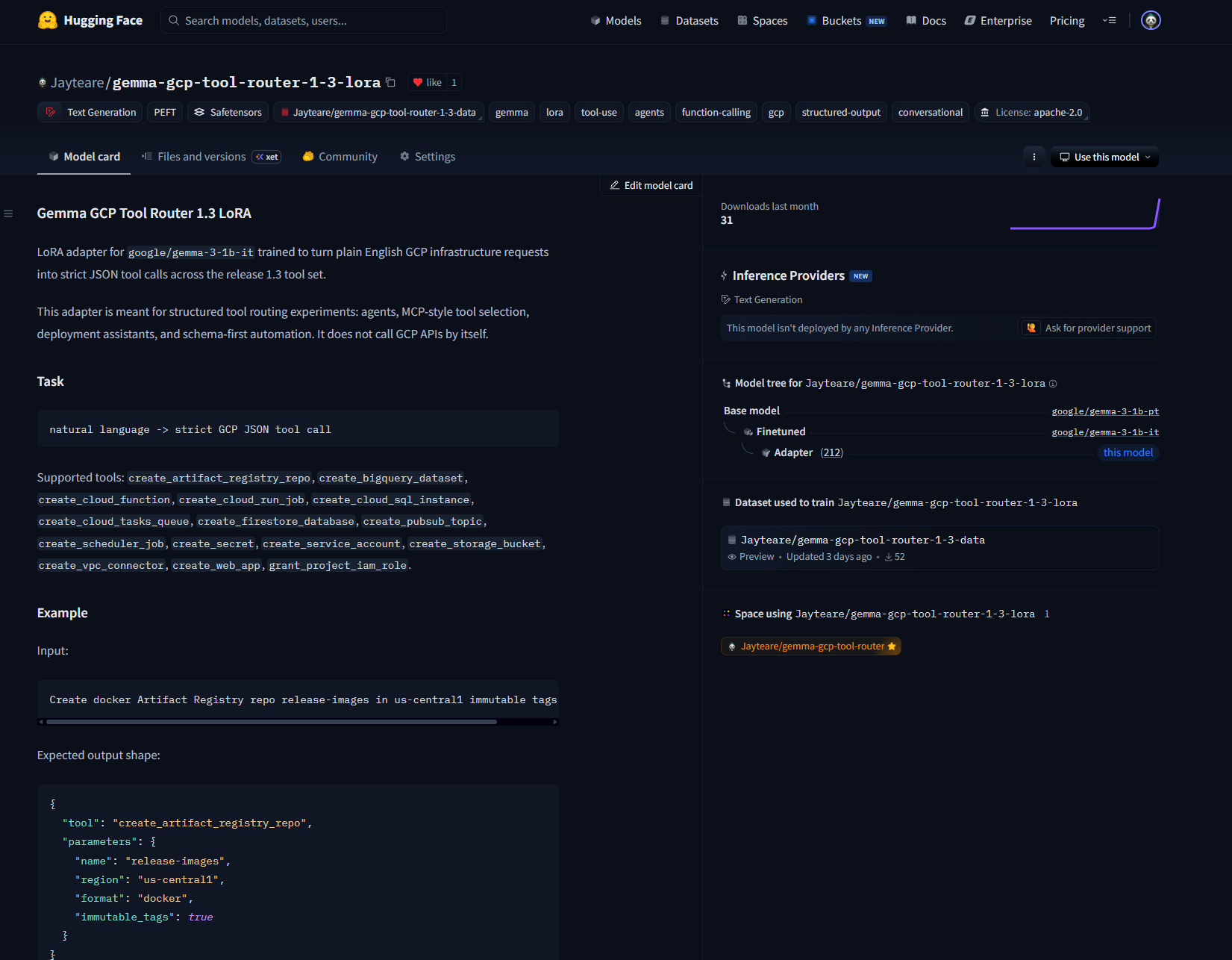
The public Hugging Face artifacts are available here:
- Dataset: Jayteare/gemma-gcp-tool-router-1-3-data
- Adapter: Jayteare/gemma-gcp-tool-router-1-3-lora
- Space demo: Jayteare/gemma-gcp-tool-router
The easiest way to test the router is through the Space demo. Paste in a request like:
Create docker Artifact Registry repo release-images in us-central1 immutable tags enabled
A good response should be one strict JSON object:
{
"tool": "create_artifact_registry_repo",
"parameters": {
"name": "release-images",
"region": "us-central1",
"format": "docker",
"immutable_tags": true
}
}
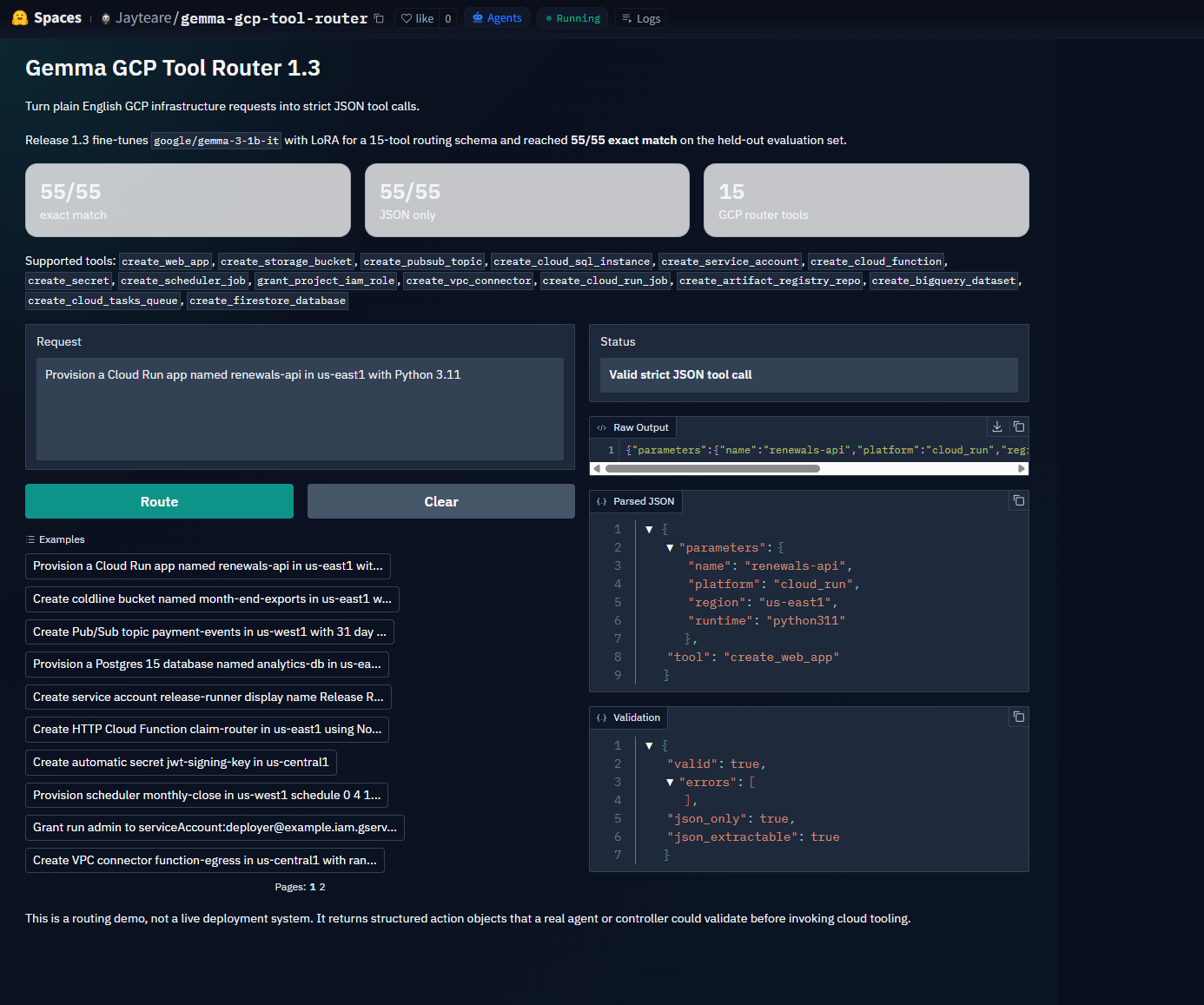
The important thing is not just that the output is JSON. It should also choose the correct tool, use the exact parameter keys, normalize the values, and avoid any extra prose before or after the object.
A useful quick check is to try a few prompts that touch different parts of the schema:
- Create docker Artifact Registry repo release-images in us-central1 immutable tags enabled
- Grant storage admin to user:ops@example.com on project analytics-prod
- Provision Cloud Run Job media-transcode in us-east1 using Go and 12 tasks with 2048 MB
- Make bq dataset session_events in us-east1 with no default table expiration
- Set up Cloud Tasks report-export in us-west1 max dispatches 60 per second max concurrent 240
Those prompts cover several of the details that mattered during training: Artifact Registry formats, IAM role prefixes, Cloud Run Jobs versus services, BigQuery expiration defaults, and Cloud Tasks queue fields.
Limitations
This release is intentionally narrow.
It is designed to test whether a small open model can perform one specific routing behavior: turn a natural-language GCP infrastructure request into a strict JSON tool call.
It does not:
- call real GCP APIs
- create Terraform
- plan multi-step systems
- handle arbitrary GCP services
- support every region or runtime
- replace validation, authorization, or policy checks
Those limitations are intentional. Release 1.3.0 focuses on the model-to-router boundary, not the full execution layer.
The right production shape would still validate the JSON, authorize the action, and execute cloud changes through a controlled tool layer. The model should not be allowed to directly mutate infrastructure just because it produced something that looks plausible.
That separation is important.
Fine-tuning can make the router more reliable, but it should not remove guardrails from the execution layer. A safer infrastructure agent should still have deterministic validation, policy checks, permission boundaries, dry-run behavior, audit logs, and human approval for sensitive actions.
In that architecture, the model proposes a structured action. The system decides whether that action is allowed.
That is the boundary this project is building toward.
What Comes Next
The natural next step is release 1.4: moving from single-action routing to small deployment plans.
Release 1.3.0 answers a narrower question: can the model turn one natural-language request into one valid JSON tool call?
The next version asks a harder question: can the model turn one higher-level infrastructure request into an ordered list of valid tool calls?
For example, a user might ask:
Create a Python API with a database, secret, service account, and scheduler job.
That should not become one tool call. It should become a plan: a list of smaller, validated actions that can be checked before anything executes.
One possible output shape could look like this:
{
"plan": [
{
"tool": "create_service_account",
"parameters": {
"account_id": "api-runner",
"display_name": "API Runner"
}
},
{
"tool": "create_secret",
"parameters": {
"name": "api-db-password",
"replication": "automatic"
}
},
{
"tool": "create_cloud_sql_instance",
"parameters": {
"name": "api-db",
"region": "us-central1",
"database_version": "postgres15",
"tier": "db-f1-micro"
}
},
{
"tool": "create_scheduler_job",
"parameters": {
"name": "api-nightly-refresh",
"region": "us-central1",
"schedule": "0 2 * * *",
"target_uri": "https://example.com/jobs/nightly-refresh"
}
}
]
}
That would turn the project from a single-action router into the beginning of a real infrastructure planning agent.
The next questions become harder:
- Can the model order tool calls correctly?
- Can it preserve dependencies between resources?
- Can it ask for clarification when required fields are missing?
- Can it refuse unsafe or ambiguous actions?
- Can a separate validator catch bad plans before execution?
- Can the system distinguish between a draft plan, a dry run, and an approved execution?
- Can policy checks block risky actions before they reach the cloud API?
This is where the project starts to move from routing into planning.
That also changes the architecture. The model should not directly execute the plan. It should propose a structured plan that another layer can inspect, validate, and either reject, revise, or submit for approval.
A future version could look like this:
user request -> model-generated plan -> schema validation -> policy checks -> dry run -> human approval -> controlled execution
That keeps the same principle as release 1.3.0: the model is useful because it produces structured objects, not because it is trusted blindly.
The long-term direction is a fuller GCP agent, but the foundation is still the same: reliable translation from language into validated infrastructure actions.
Closing
The interesting part of this project is how small and concrete it is.
It is not a giant agent framework. It is not a vague “AI for cloud” prototype. It is one narrow behavior, measured carefully:
Can the model turn an English infrastructure request into the exact JSON object a tool router needs?
For release 1.3.0, the answer was yes.
Base Gemma gave a useful starting point. It often understood the rough shape of the task, but it was not reliable enough for structured automation.
The frozen 1.2 adapter showed partial transfer to the expanded schema. That was useful because it proved some of the routing behavior carried forward, but also showed that new tools and new schema details still needed targeted training.
LoRA fine-tuning for 1.3 turned that partial behavior into reliable structured output across 15 GCP-style tools.
The result is a compact example of how small open models can be trained for agentic cloud automation tasks.
But more importantly, it shows a practical development pattern:
- define a narrow tool surface
- create strict schemas
- fine-tune for the routing behavior
- evaluate against held-out prompts
- inspect failures
- add targeted examples
- expand the tool surface gradually
That pattern is the part I want to keep building on.
The long-term goal is a fuller GCP agent, but the foundation has to be boringly reliable first. Before an agent can plan deployments or execute infrastructure changes, it needs to translate intent into validated action objects.
Release 1.3.0 is one step in that direction.
It turns natural-language cloud requests into structured tool calls that can be parsed, checked, and routed.
That feels like the right foundation to build on.